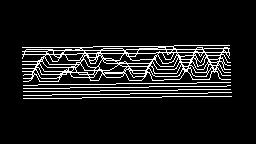
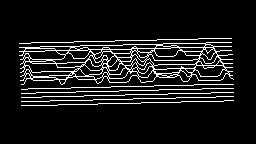
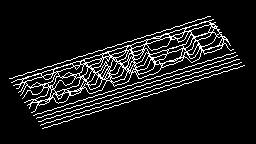
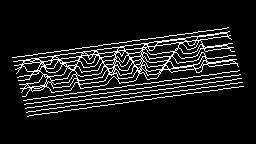
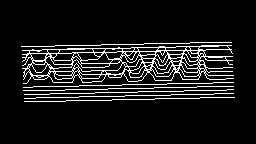
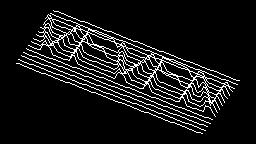
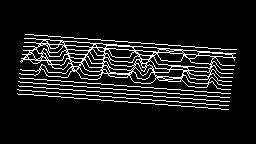
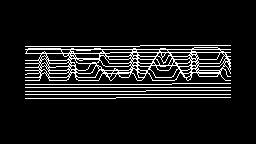
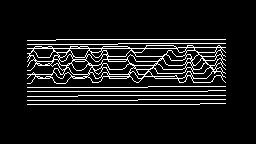
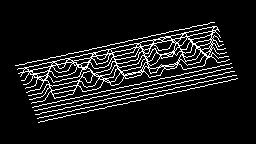
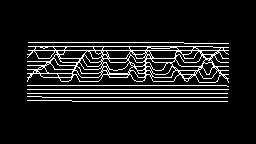
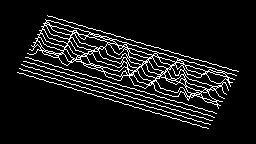
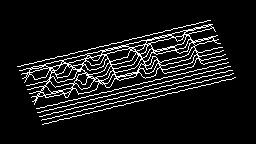
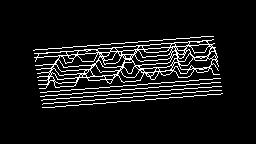
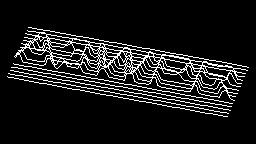
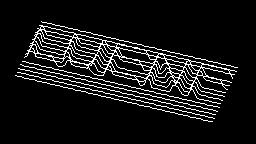
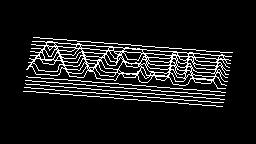
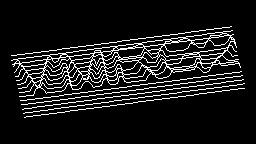
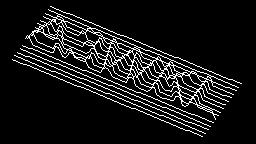
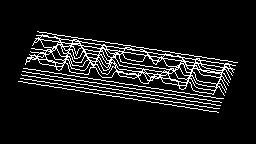
Scale-variant items where text is rendered as shapes within figures, appearing as text when reduced and resolving into complete images when magnified. 150 images
Recognition challenges constructed with curved characters in three-dimensional space, testing spatial reasoning capabilities. 150 captchas
Similar to Ishihara tests, but augmented with confounding colored dots that are chromatically similar to central characters to increase difficulty. 150 test images
Intricate complex glyphs synthesized through character decomposition, morphological transformation, and fusion of multiple Chinese characters into different words or phrases.

World

China

France

Music

Cat

Water

Sun

Child

Coffee

Snow

Phone

Money

Train

Bridge

Door

Window

Boston

Key

Love

Tooth

Rice

Card

Magic

Berlin

Beach

Clean


Juice

Sound

Happy

Fresh

Mexico

Peace

Sydney

Smoke

Pillow
| Models | Param | Date | HiddenText | 3DCaptcha | ColorBlind | ChineseLigatures | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pass@1 | Pass@32 | Pass@1 | Pass@32 | Pass@1 | Pass@32 | Pass@1 | Pass@32 | |||
| GPT-5 | - | 2025-08 | 0 | 0.67 | 0 | 0 | 3.33 | 16 | 2.5 | 2.5 |
| GLM-4.5V | 106B(12B act.) | 2025-08 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Grok-4 | - | 2025-07 | 0 | 1.33 | 0 | 0 | 0 | 0 | 0 | 2.5 |
| Seed-1-6 | 230B (23B act.) | 2025-06 | 0 | 0 | 0 | 0 | 0 | 0 | 2.5 | 2.5 |
| Show o2 | 7B | 2025-06 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Claude-4-Sonnet | - | 2025-05 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Gemini 2.5 Pro | - | 2025-05 | 0 | 0 | 0 | 0 | 0 | 0 | 2.5 | 5.0 |
| Bagel | 14B (7B act.) | 2025-05 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| kimi-vl-a3b | 16B (3B act.) | 2025-04 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5.0 |
| kimi-vl-a3b-thinking | 16B (3B act.) | 2025-04 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| InternVL3-78B | 78B | 2025-04 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Qwen2.5-Omni-7B | 7B | 2025-03 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2.5 |
| MiniCPM-o-2.6 | 8B | 2025-01 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2.5 |
| Janus-pro | 7B | 2025-01 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Qwen2.5VL-72B | 72B | 2025-01 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Qwen2.5VL-7B | 7B | 2025-01 | 0 | 0.67 | 0 | 0 | 0 | 0 | 0 | 2.5 |
| OpenAI o1 | - | 2024-12 | 0 | 0 | 0 | 0 | 0 | 1.33 | 0 | 0 |
| QVQ-72B | 72B | 2024-12 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Pass@1 and Pass@32 performance of 15 MLLMs on four tasks of TET. The results show universally poor performance across all models and tasks, highlighting the severity of the vision blind spot.
While ViT allocates attention across various regions of the image, this attention is often directed outside the target character regions or only captures partial segments. The image encoder struggles to effectively focus on textural features corresponding to character regions and instead prioritizes object-level features within the image. Such disparities in visual attention prevent the model from truly comprehending the image content.
LLM decoders consistently fail to focus on the precise regions containing text or character information; instead, they scatter attention over irrelevant regions or completely ignore critical visual elements. This inconsistency between attention patterns and actual locations of important visual features indicates fundamental limitations in visual perception ability.

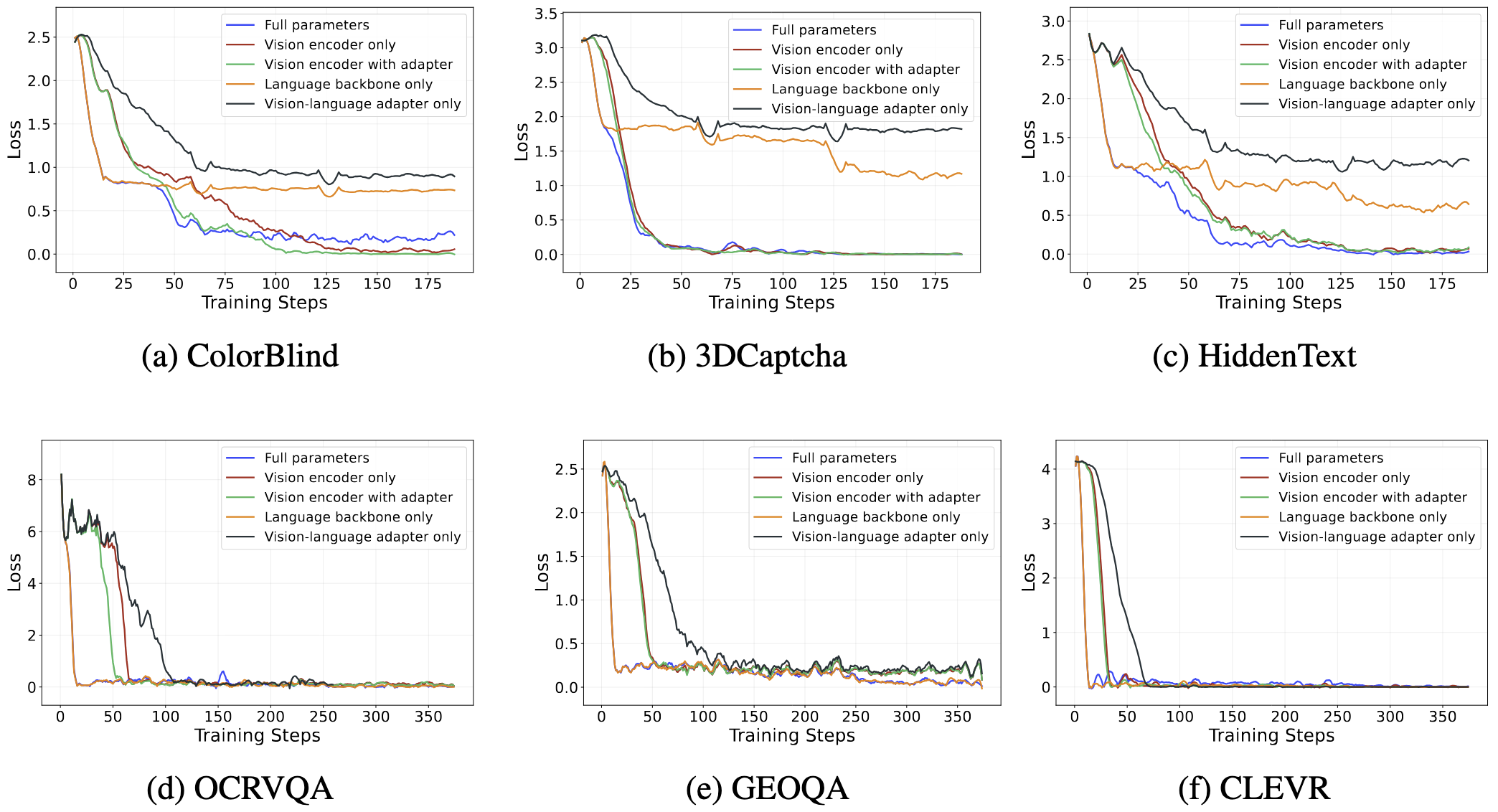
Training loss curve for different settings on finetuning parameters for both our tasks and traditional tasks.

@misc{gao2025pixelspatternspoetryworld,
title={Pixels, Patterns, but No Poetry: To See The World like Humans},
author={Hongcheng Gao and Zihao Huang and Lin Xu and Jingyi Tang and Xinhao Li and Yue Liu and Haoyang Li and Taihang Hu and Minhua Lin and Xinlong Yang and Ge Wu and Balong Bi and Hongyu Chen and Wentao Zhang},
year={2025},
eprint={2507.16863},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.16863}
} Pixels, Patterns, but no Poetry:
To See the World like Humans
Pixels, Patterns, but no Poetry:
To See the World like Humans